AI and Content Moderation for Online Hate Speech: Can LLM-based Counterfactuals Help? Prof Arjumand Younus
Arjumand Younus
AI and Content Moderation for Online Hate Speech: Can LLM-based Counterfactuals Help?
Prof Arjumand Younus
There is no doubt that the World Wide Web has given an expressive power to its users, and there have been multiple occasions when this power has been put to good use such as during Arab Spring 2011. More recently however with growing tendencies towards jingoism and right-wing rhetoric, there has been a tendency to misuse digital platforms leading to the phenomenon of online hate speech. In fact as of 2015 UNESCO reports that in EU alone, 80% of people have encountered hate speech online while 40% have felt attacked or threatened online (Gagliardone et al. 2015). This has led digital platforms and social media companies to take action in the form of content moderation defined primarily as process of reviewing and monitoring user-generated content so it meets certain standards and guidelines (Gillespie, 2018); and earliest forms of such moderation involved a human-in-the-loop paradigm whereby human moderators make a decision on whether to remove a “perceived harmful” post (Kozyreva et al., 2023). The unprecedented scale at which digital platforms enable the production of content together with significant technical advances in machine learning meant the use of automation in content moderation systems, and a phenomenon within tech industry where artificial intelligence is overambitiously “hailed” as a silver bullet for challenges around online hate speech (Llansó, 2020).
The reality however is that manual efforts by human moderators are still an inevitable part of hate speech content moderation systems (Wagner et al., 2021); and this inevitability stems from the bias embedded within artificial intelligence in terms of its limitations to punish certain terms. This in most cases leads to stifling voices of marginalized groups (see Figure 1), and punishing them due to an AI model learning features of a dataset which in this case is related to term “black.”
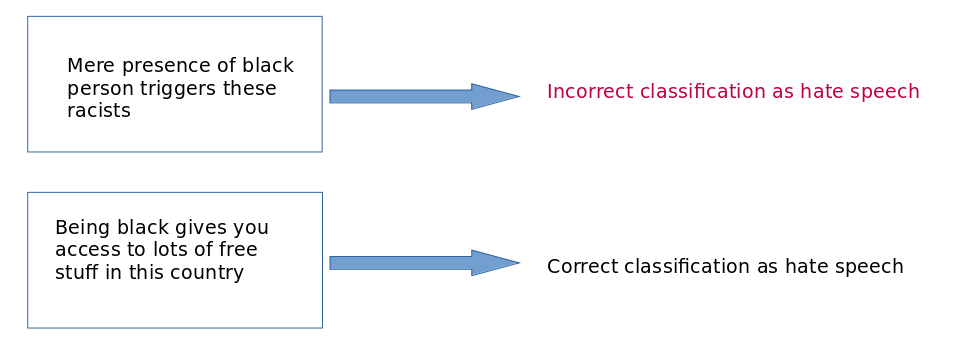
Figure 1: Example of Incorrect Classification with Automated Hate Speech Detection |
One solution to this problem that the the natural language processing research community has turned towards comes from the fields of historiography and psychology using a construct called “counterfactuals” whereby alternate sentences are created (see Figure 2) using various operators such as deletion, negations, and substitutions. In a pure AI and specifically, machine learning context this helps detatching the algorithm from the learning of terms and helps produce robust hate speech detection models meaning they do not misclassify in most instances.

Figure 2: Examples of Counterfactuals with Edit Types |
The counterfactual generation process however mostly involves manual effort (Kaushik work), and the chief improvement comes from augmentation of machine learning’s training data with the counterfactually-generated examples for enhanced learning of feature sets. Essentially, this would mean that the instances of incorrectly stiflling marignalized voices will not occur every so often as was the case in the first example of Figure 1.
Dr Arjumand Younus of UCD’s Centre for Digital Policy in collaboration with Dr Muhammad Atif Qureshi who is Director of Explainable Analytics Group at TU Dublin and Dr Simon Caton of School of Computer Science in UCD explored the usefulness of large language models for the automatic generation of counterfactuals corresponding to a hate speech detection task. The two classes of large language models they experimented with were Polyjuice (Wu et al., 2021) and ChatGPT (Waghmare, 2023) and both of them use GPT(generative pretrained transformers) as their underlying methodology. Using case-study examples from previous hate speech datasets they first argue how manual generation of counterfactuals incorporate subjectivity cues (see Figure 3) which also leads to retaining some amount of offense in the counterfactuals. Furthermore, the use of free-form LLM-generated counterfactuals helps approach the problem of hate speech detection in a fundamentally different way without resort to cancel culture (Clark, 2020): the second example in Figure 3 shows that a more expressive form of a counterfactual that ChatGPT generates; and these counterfactuals are not restricted to basic edits or label flips.
Another significant aspect of this work is inclusivity having been injected into the automation in counterfactuals’ generation through using large language models to generate only non-hate speech texts from hate speech texts and not vice versa unlike previous approaches (Sen et al., 2023). The non-hate counterfactuals with the original training data is then used to train well-known machine learning models to test their performance against manually counterfactuals and our extensive evaluations on standard hate speech datasets show that mixing LLM-generated counterfactuals from both Polyjuice and ChatGPT can outperform manual methods.
Overall this work is a step in the direction of AI-based content moderation through LLMs showing great promise and we argue that with a more crititcal and careful examination of current datasets and algorithms we can move towards maximum human-in-the-loop reduction. Finally as an answer to the question posed in the title: human-in-the-loop continues to occupy an important role when it comes to content moderation for online hate speech but with a focus on embedding inclusivity in algorithms we can improve our current AI systems.
|
Figure 3: Original Sentence vs Manual Counterfactual vs ChatGPT-based Counterfactual |

References
Gagliardone, I., Gal, D., Alves, T., & Martinez, G. (2015). Countering online hate speech. Unesco Publishing.
Gillespie, T. (2018). Custodians of the Internet: Platforms, content moderation, and the hidden decisions that shape social media. Yale University Press.
Kozyreva, A., Herzog, S. M., Lewandowsky, S., Hertwig, R., Lorenz-Spreen, P., Leiser, M., & Reifler, J. (2023). Resolving content moderation dilemmas between free speech and harmful misinformation. Proceedings of the National Academy of Sciences, 120(7), e2210666120.
Llansó, E. J. (2020). No amount of “AI” in content moderation will solve filtering’s prior-restraint problem. Big Data & Society, 7(1), 2053951720920686.
Wagner, C., Strohmaier, M., Olteanu, A., Kıcıman, E., Contractor, N., & Eliassi-Rad, T. (2021). Measuring algorithmically infused societies. Nature, 595(7866), 197-204.
Wu, T., Ribeiro, M. T., Heer, J., & Weld, D. S. (2021, August). Polyjuice: Generating Counterfactuals for Explaining, Evaluating, and Improving Models. In Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers) (pp. 6707-6723).
Waghmare, C. (2023). Introduction to ChatGPT. In Unleashing The Power of ChatGPT: A Real World Business Applications (pp. 1-26). Berkeley, CA: Apress.
- Clark, M. (2020). DRAG THEM: A brief etymology of so-called “cancel culture”. Communication and the Public, 5(3-4), 88-92.
Sen, I., Assenmacher, D., Samory, M., Augenstein, I., Aalst, W., & Wagner, C. (2023, December). People Make Better Edits: Measuring the Efficacy of LLM-Generated Counterfactually Augmented Data for Harmful Language Detection. In Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing (pp. 10480-10504).
————————————————————————————————————-
For a detailed version of this work we refer the reader to the full paper